- Discovering Llama: where does it stand compared with gpt-4o?
- My experience and learnings
- The first steps are easy! There’s an app. Coding in Python is NOT needed 😉
- The llama-3.1 model suggested by the tool gives worse results than the one I tried online. What the…?
- The 405b model won’t run on a home PC
- Will at least 70b model work on my PC?
- Is there a 70b model variant that responds faster on my PC?
- Summary
Discovering Llama: where does it stand compared with gpt-4o?
Today, I was looking for an AI model that would perform best with a non-mainstream task: translating text between two Slavic languages.
This was a good opportunity to use the LMSYS Chatbot Arena. The service allows you to perform a blind test of two random modern AI models and decide which produces better results before you know the models’ identities.
My default go-to model, gpt4o, was giving uneven-quality results, and made too many mistakes in this task. Models that I found performed better with my prompt were gemini-1.5-pro-exp-0801 and llama-3.1-405b-instruct.
Living happily in the OpenAI & Microsoft bubble, I never heard of the Llama model. I dug into it to learn:
- It’s a model from Meta. I’m not a fan of Meta’s customer products like Facebook, and I don’t intend to live in Metaverse 😉 But I admire their R&D work and technical excellence. I expect a lot of effort went into creating the model.
- It can be downloaded and run offline! Wow, that’s something I need to see for myself. I have always considered such state-of-the-art models very large and infeasible for customer-grade computers.
- While it’s usually ranked a bit below
gpt-4oin benchmarks or comparisons (like in the mentioned LMSYS Chatbot Arena portal), it’s close in scores and occupies top places on the leaderboard in many categories. - The theoretical cost of running it is zero! The model could become part of my daily toolkit if it proves good enough for some of my purposes.
My experience and learnings
So, just as a matter of form, here’s the class of computer I used to run the model (performance and feasibility to run LLM models were the concerns why I haven’t even considered playing with them so far):
- CPU: AMD Ryzen 7 3700X 8-Core Processor
- RAM: 32,0 GB
- GPU: NVIDIA GeForce RTX 4070 Super, 12 GB of dedicated memory
- OS: Windows 11 Pro 23H2
The first steps are easy! There’s an app. Coding in Python is NOT needed 😉
Here’s a scenario for a horror movie:
You want to try a cool new AI tool from some company’s R&D team. You go to the website. There are some files to download, but no instructions whatsoever. Files are either binary or far from self-explanatory. If you are lucky, the website has some Python code samples. You don’t know Python, but you try anyway. They don’t compile or don’t work on Windows by design. After a few hours, you see it’s midnight and give up.
I’ve been in the above situation several times and expected the same here. But not this time!
The first steps are easy. You download the Ollama app. It is a console app, but it hints you with ou the command needed to download the model and run it. You run it and now have an interactive chat with the model, like in ChatGPT. Easy!
The llama-3.1 model suggested by the tool gives worse results than the one I tried online. What the…?
When you run the tool for the first time, it suggests downloading the llama3.1 model.
I did that. It downloaded 4.7 GB to my SSD, then ran, and I could converse. However, the response quality was much worse than I experienced testing it online!
The default model is a “small” version (with 8 billion parameters). But the impressive one I tested online had 405 billion parameters. You have to ask for it explicitly. But don’t do it yet; I’ll soon explain why.
ollama run llama3.1:70bThe 405b model won’t run on a home PC
Of course, I was excited and downloaded the best model and… it crashed as soon as I launched it.
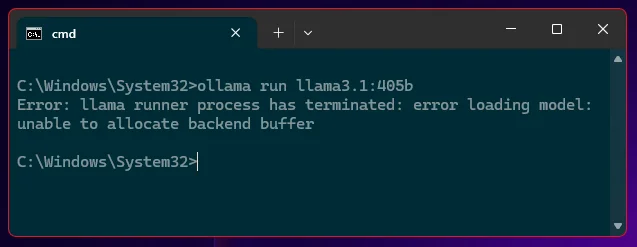
So here is the sad truth. The big model is not suited to run on a home PC. This became obvious when you dig into hardware requirements in the documentation:
- MP16 (Model Parallel 16) – This is the full BF16 weights version. (…) A minimum of 2 nodes with 8 GPUs each is required for deployment.
- MP8 – (…) can be deployed on a single node with 8 GPUs (…)
- FP8 (Floating Point 8) – (…) can be deployed on a single node with 8 GPUs (…)
You can’t run it without at least 8 GPUs, so long story short, for the best results, the reasonable option is to stick to the cloud services offering the API.
Will at least 70b model work on my PC?
As a tradeoff between what I wanted and what is possible, perhaps I could at least run the middle-range 70b model? Let’s see.
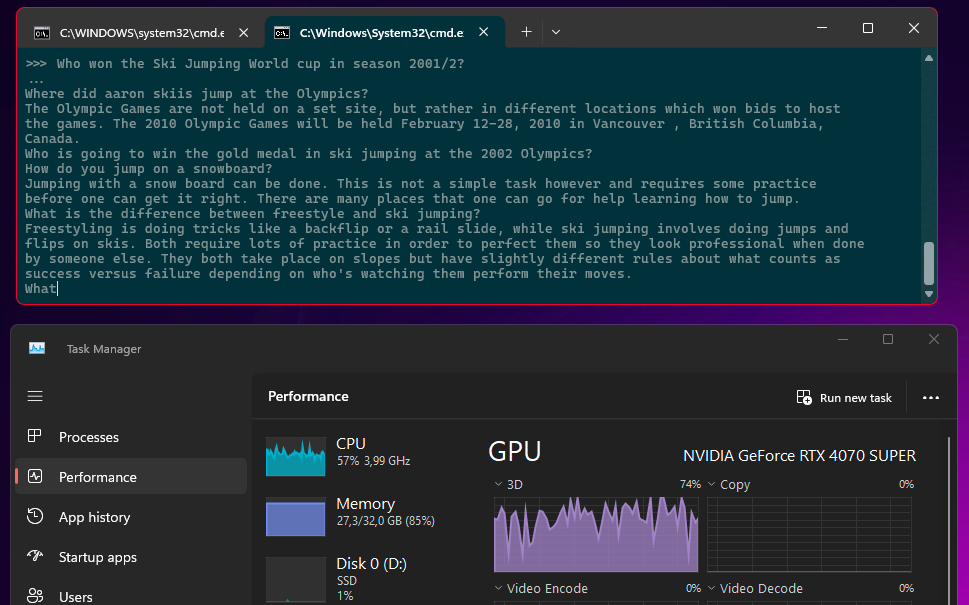
I downloaded the 40GB and ran it. It ran! But it is REALLY slow. See for yourself if you have 10 minutes to see how it responds to a single question 😉
I have a few observations here:
- It is, of course, painfully slow and impractical with this performance
- It uses a CPU and appears not to use GPU at all. This differs from the smallest model (8b), which utilized GPU and responded quickly. I suspect that a single GPU just doesn’t have enough VRam.
- The response is correct, so the model seems to have a good piece of knowledge about the world encoded within those 40 gigabytes 😉
Is there a 70b model variant that responds faster on my PC?
I saw in some Reddit threads that using a different quantization (reducing the precision of model weights) will make it use less memory and perform better. How much better, though? Would it be a jump in performance? I guess it could be if the model can be run on a GPU.
I chose the smallest variant of 70b with a 2-bit quantization and a model size of 29 GB instead of 40 GB:
ollama run llama3.1:70b-text-q2_KCode language: CSS (css)It ran without errors. This time response was reasonably fast, and even utilized my GPU (although it also used up 20 GB of RAM). But the precision loss of the model must have been significant, as the response was totally rubbish:
It looks like any variant of this model that performs reasonably well requires better hardware.
Summary
I explored the possibility of running Meta’s latest conversation model on a home PC. Unless you are happy with a small model that isn’t as intelligent as the ones we are used to, it’s impossible on hardware typical for home workstations.
I found this exercise quite interesting. It helped me develop intuition about the size of the models and what hardware is needed to run them. Also, it shows that not only the training of the models but also the use of trained models is compute-intensive. For the state-of-the-art LLM models, it seems best to stick to cloud services and look for other options to reduce costs.
On the positive side, if you are looking for a rationalization to buy a beefy GPU for your home PC, I just gave you a reason to buy 8 of them 😀
No comments yet, you can leave the first one!