
What is Query Acceleration
Query acceleration is a feature in Azure Blob Storage that can be handy if you use Data Lake (or general Blob Storage) to keep your data.
The feature allows server-side filtering of data, assuming it’s in one of the supported formats, like JSON or CSV. It can result in limiting the data transferred between Data Lake Storage and a client application that reads it. This diagram from “Azure Data Lake Storage query acceleration” explains in well (see the whole document for high-level feature’s overview:
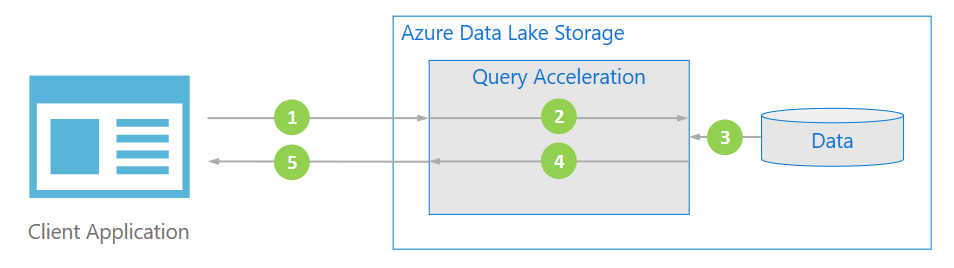
Example: filtering data in a “JSON lines” file in Data Lake
In one of our company projects, we store our data in large Data Lake files that contain one JSON document in each line. Some people call this file format “JSON lines”. Here is an example of a file in that format:
// people.jsonl: an example demo file in Data Lake Storage Gen2 (or Azure Blob Storage in general)
{ "Name": "Christopher", "Address": { "City": "Cleveland", "State": "Ohio" } }
{ "Name": "Lowell", "Address": { "City": "Nashville", "State": "Tennessee" } }
{ "Name": "Adam", "Address": { "City": "Sunray", "State": "Texas" } }
{ "Name": "David", "Address": { "City": "Austin", "State": "Texas" } }
Code language: JSON / JSON with Comments (json)The benefit of storing multiple JSON documents in a single file comes mainly from the fact that systems like Data Lake are optimized to handle large files, rather than numerous small files. For example, the documentation recommends: “organize your data into larger sized files for better performance (256 MB to 100 GB in size)”.
But what if we have a use case where we only need to read few specific lines from such a huge 100-gigabyte document? Downloading the whole file would be slow and cost-ineffective. But query acceleration comes to the rescue!
Here’s a code sample that allows to query the above document and only download records with Address.State = "Texas":
// this project references NuGet package: Azure.Storage.Blobs, 12.8.0
using Azure.Storage.Blobs.Models;
using Azure.Storage.Blobs.Specialized;
var connectionString = "DefaultEndpointsProtocol=https;AccountName=CENSORED;AccountKey=CENSORED;EndpointSuffix=core.windows.net";
var blobContainerName = "mycontainer";
var blobName = "people.jsonl";
BlockBlobClient client = new BlockBlobClient(connectionString, blobContainerName, blobName);
var options = new BlobQueryOptions()
{
InputTextConfiguration = new BlobQueryJsonTextOptions(),
OutputTextConfiguration = new BlobQueryJsonTextOptions()
};
var queryText = "SELECT * FROM BlobStorage WHERE Address.State = 'Texas'";
var response = client.Query(queryText, options);
var responseContent = await new StreamReader(response.Value.Content).ReadToEndAsync();
Console.WriteLine($"The following query:\n");
Console.WriteLine($" {queryText}\n");
Console.WriteLine($".. produced the result:\n");
Console.WriteLine(responseContent);
Code language: C# (cs)The result is:
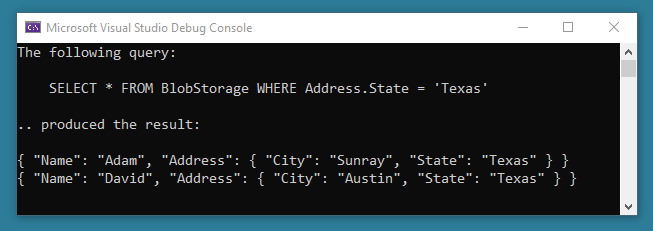
My observations
Some observations before I conclude:
- When I tested this feature, it worked nicely in a slightly outdated version of
Azure.Storage.BlobsNuGet package, 12.8.0. The most recent version, 12.10.0, gives me an unclearAzure.RequestFailedException: 'XML specified is not syntactically valid. Status: 400. Maybe my timing to learn about this was unlucky, but maybe this feature is not a first class citizen and doesn’t get enough attention? I don’t know. - While this is marketed as a feature of Data Lake, this naming is misleading. It’s part of the Blob Storage API. It’s available in blob storage even if we don’t enable the Data Lake hierarchical namespace feature. For the same reason, it’s only available in Data Lake Gen2 which is based on Blob Storage, and not in older Data Lake Gen1.
- Documentation warns that accelerated queries come with additional cost. But if your use case fits the scenario, it should generally be cheaper and faster. In the end, that’s the whole point.
Thanks for stopping by!
No comments yet, you can leave the first one!