The problem: Copilot cannot browse the web
One of the limitations of the default GitHub Copilot installations in Visual Studio Code I was kind-of aware of, but never really focused on, is in its inability to access internet websites, or search the web.
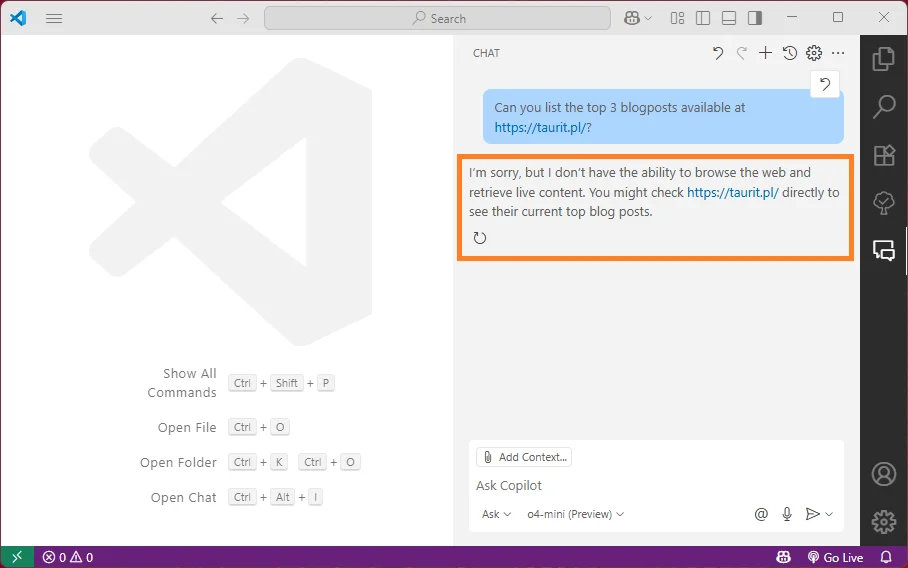
It turns out to be inconvenient, especially when working with niche libraries and tools. Sometimes the documentation exists on the internet, and as a developer I could even point out where it is. But the AI models seem to never be trained on it, or were trained on an outdated version, or the information was too scarce and LLMs hallucinate.
Why fetching pages is more complex than it might seem
Granting models the ability to use search engines and access internet was already in preview last year. I expected it would soon land in GitHub Copilot. But it has not happened.
Here is my pure speculation why it didn’t happen. And I think it might not happen so soon, so spending time on additional configuration might be still worth the effort to gain productivity:
- Fetching page is not as trivial as it might seem at first glance. Internet in 2025 is build on dynamic, JavaScript-based pages. It is rarely enough to download the document under the URL and parse it. The task is closer to having a text-based internet browser to fetch the page, execute JavaScript, and render the website as text, and ideally denoise it for LLM. There is a growing market for tools that help scrape the web for LLMs.
- Searching the internet is an additional layer of complexity. Integration with Search APIs like Google Search is not free (or at least not free in the scale needed to enable it by the default for everyone). And I can see how it can be seen as beyond the scope of add-on like GitHub Copilot. With MCP standard, this can be better delegated to other addons or MCP tools.
Overcoming the problem: let the Copilot fetch URLs!
Long story short, I recommend installing a good addon that will extend the Copilot tool palette with the ability to fetch web pages. The one I found and appears trusted is Microsoft’s Web Search for Copilot.
Simply installing it adds the ability to fetch page content:
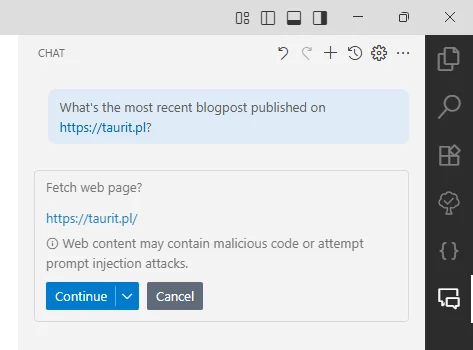

Enabling the search
Let’s try teach it to search now! I’ll continue setting up Web Search for Copilot to add search capability. This time the extension also leads me step by step through the configuration. By default it uses the Tavily Search API dedicated for use by LLMs.
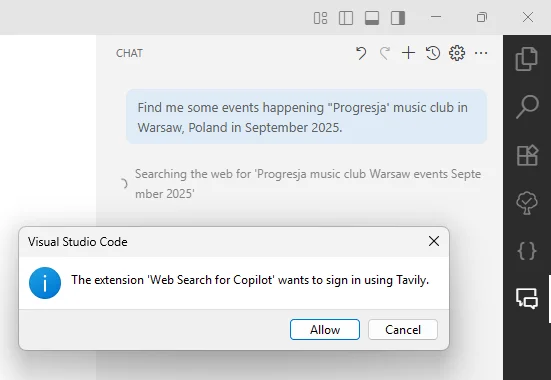
The setup was as easy as I could imagine and took 1 minute. I signed in with my Google Account, approved the login, and was instantly redirected to the dashboard with the API Key and usage stats. The pricing seems affordable, and if the search engine proves to be good, I’ll just stick with it long term.
The result looks correct. Copilot found and fetched the heavily-scripted page, and correctly parsed the data. Fresh results, and no hallucinations 🍄🤪
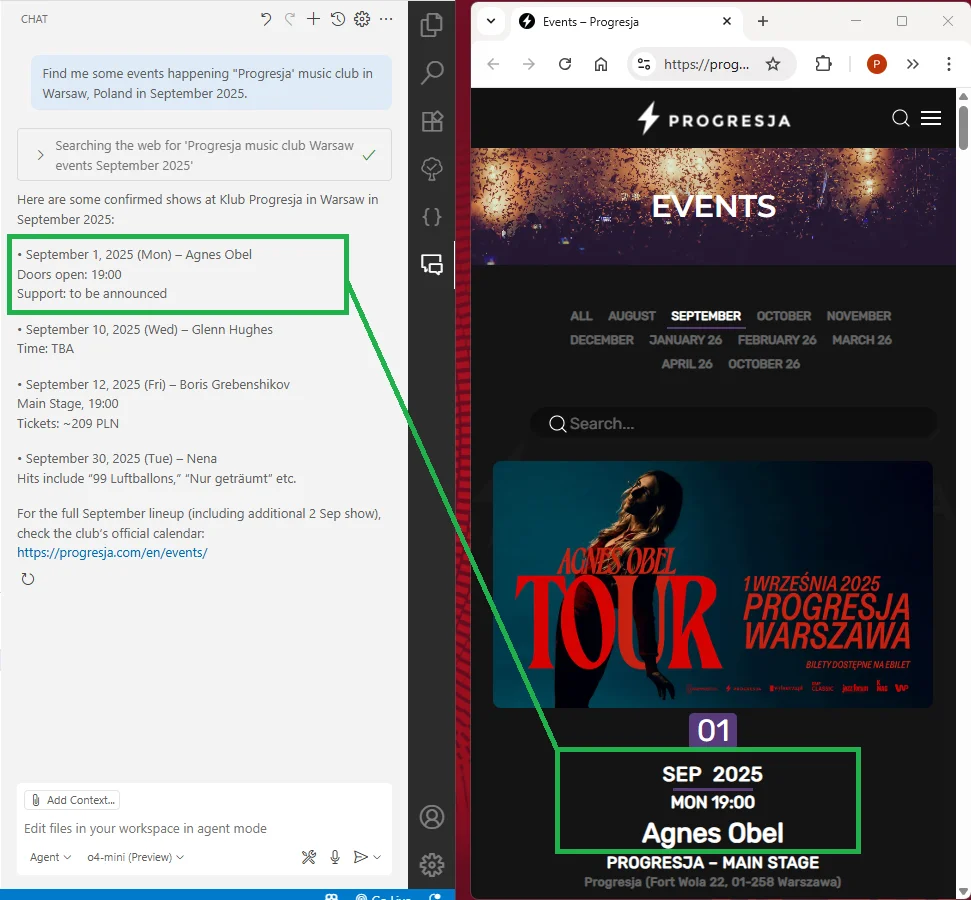
I’ve not had time to sign up and experiment with MCP servers offering Google search or other generic-purpose search engines, but regardless of the differences, Tavily is still a big improvement allowing Copilot to find and access recent documentation.
Summary
For a long time, Large Language Models had a knowledge cutoff date far in the past because of all the steps required to sanitize the data, train, and release the model. It seemed that if we wanted good support from AI tools in software development projects, we’d have to rely on older technologies and stay away from the cutting edge.
But this gap is getting narrower. Models are now being retrained more frequently, and the ones I use for coding have a knowledge cutoff only 3 to 4 months ago. Still, with web search and internet access, we can close this gap even further and give our Copilot access to up-to-date documentation and threads about known issues.
This should allow us, developers, to keep project libraries and frameworks up-to-date and still keep the power of GitHub copilot for the added productivity.
No comments yet, you can leave the first one!